AI Research & Experimentation.
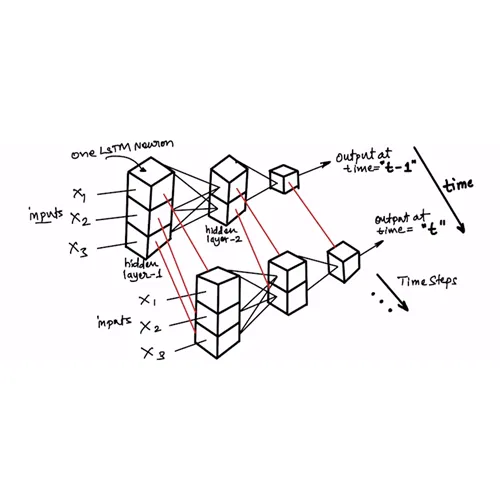
Research-driven exploration of Machine Learning models, training methods, evaluation strategies, and real-world performance constraints.
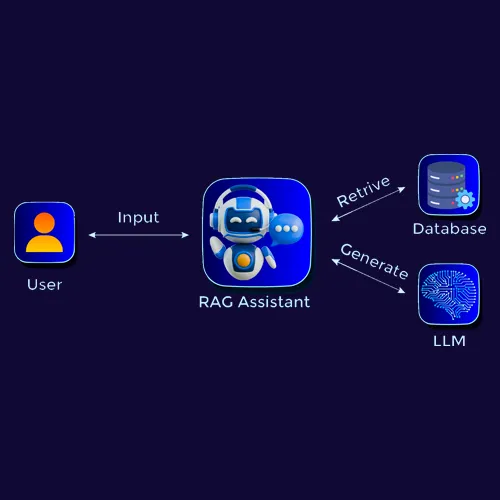
Semantic Search
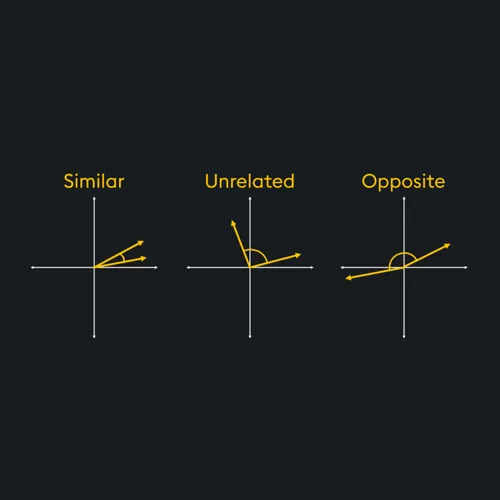
Unlike traditional keyword-based search, Semantic Search understands the meaning behind your query using LLM and vector embeddings. It matches your input with the most relevant results, even if the exact words aren't used.
DemoAI Forecast
AI brings a new level of intelligence to financial forecasting. By learning from historical data, market signals, and external factors, it helps businesses and investors predict future trends with greater accuracy.
DemoAI Chatbot
The AI chatbot is designed for seamless, human-like conversations. It understands context, detects intent, and delivers accurate responses, whether you're asking simple questions or seeking deeper insights.
DemoOCR
Optical Character Recognition (OCR) technology transforms text from images into editable, structured data you can use instantly. With Computer Vision, it saves time, reduces manual errors, and unlocks the full potential of your data.
DemoSpeech To Text
Speech-to-Text (STT) technology transforms spoken words into precise, structured text. By leveraging AI and NLP, it saves time, improves accuracy, and turns conversations, meetings, and audio files into searchable, actionable data.
Demo








Build your AI product.
I help innovators and founders bring their AI ideas to life, from strategic planning and MVP design to full-scale development and deployment. Whether you're starting from scratch or need technical support, I'm your AI partner every step of the way.
My Services