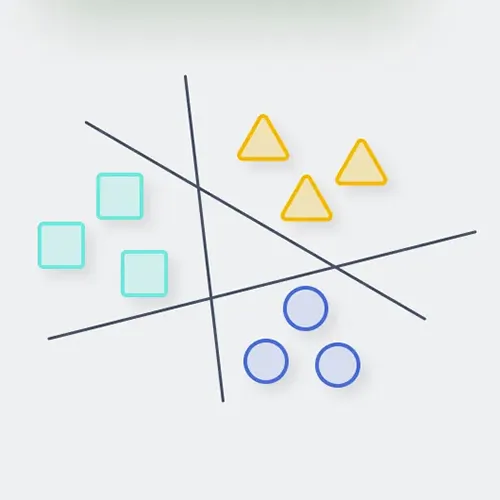
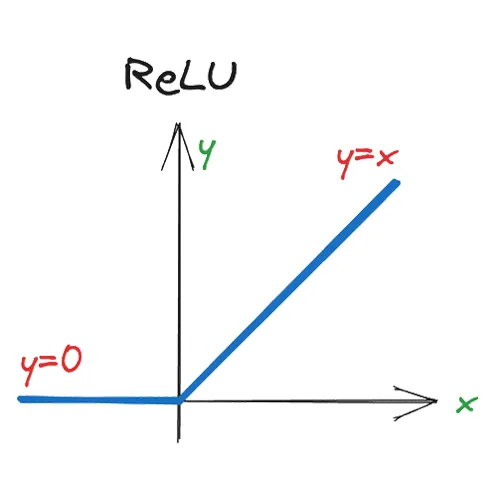
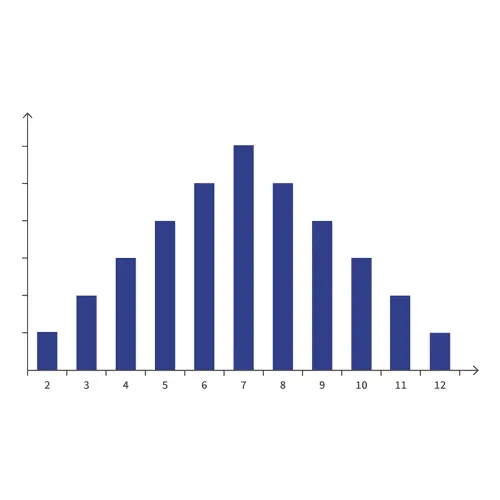
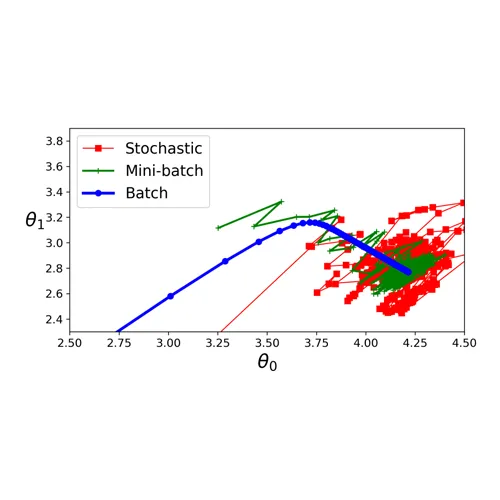
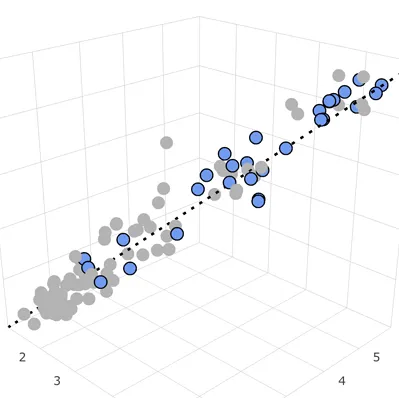
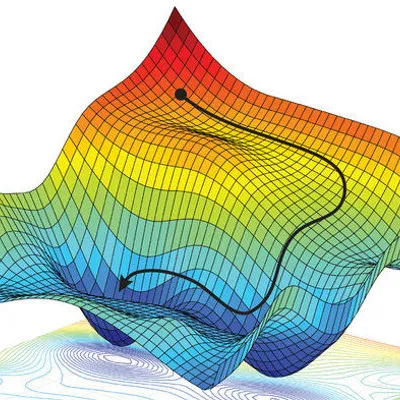
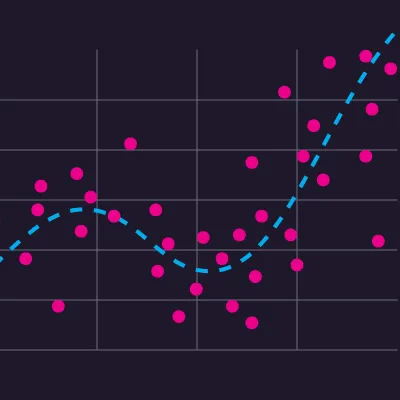
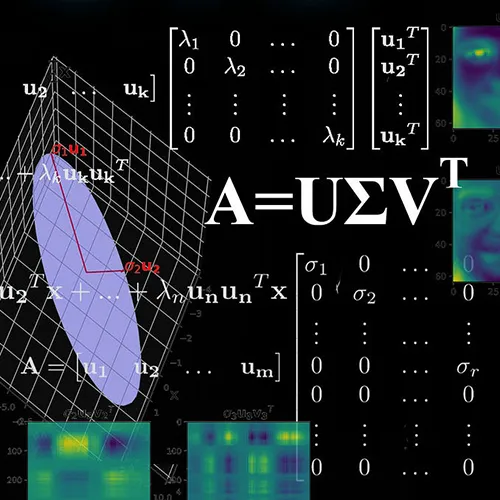
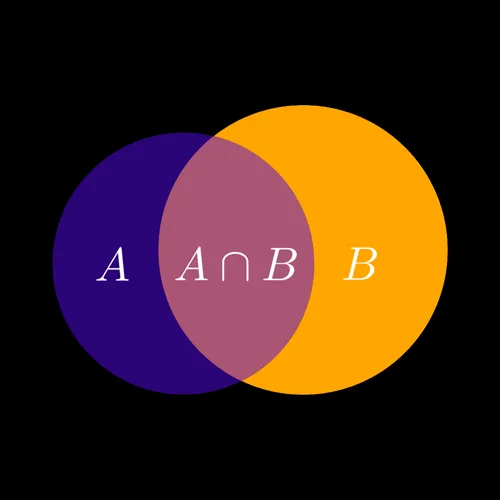September 8, 2024
September 6, 2024
September 5, 2024
September 1, 2024
July 16, 2024
July 12, 2024
June 4, 2024
November 25, 2023
November 4, 2023
September 19, 2023
August 21, 2023
April 29, 2023